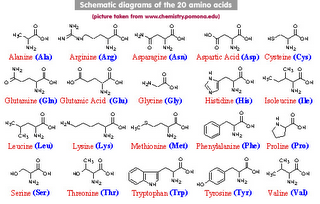
The one-letter and three-letter abbreviation codes for amino acids for example, used in UniProtKB/Swiss-Prot are those adopted by the commission on Biochemical Nomenclature of the IUPAC-IUB and are as follows (numbers give frequencies):
A Ala 7.49 Alanine
R Arg 5.22 Arginine
N Asn 4.53 Asparagine
D Asp 5.22 Aspartic acid
C Cys 1.82 Cysteine
Q Gln 4.11 Glutamine
E Glu 6.26 Glutamic acid
G Gly 7.10 Glycine
H His 2.23 Histidine
I Ile 5.45 Isoleucine
L Leu 9.06 Leucine
K Lys 5.82 Lysine
M Met 2.27 Methionine
F Phe 3.91 Phenylalanine
P Pro 5.12 Proline
S Ser 7.34 Serine
T Thr 5.96 Threonine
W Trp 1.32 Tryptophan
Y Tyr 3.25 Tyrosine
V Val 6.48 Valine
B Asx Aspartic acid or Asparagine
Z Glx Glutamic acid or Glutamine
X Xaa Any amino acid
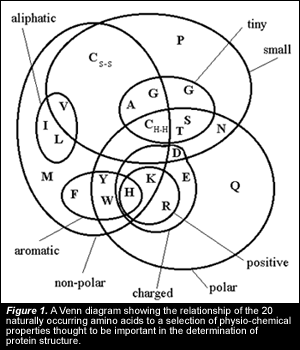
Amino Acid Properties and Substitutions
A substitution is more likely to occur between amino acids with similar biochemical properties. For example the hydrophobic amino acids Isoleucine(I) and valine(V) are more likely to substitute for one another than the hydrophilic amino acid cystine would with one of these. Amino acids come in the following types.
1. Amino acids with aliphatic hydrophobic side chains
The hydrophobic side chains of these amino acids will not form hydrogen bonds or ionic bonds with other groups. These hydrophobic amino acids tend to be buried in the centre of proteins away from the surrounding aqueous environment.
Ala, Val, Leu, lle, Met, Pro, Phe, Trp.
2. Amino acids with uncharged but polar side chains
The side chains of these amino acids are uncharged at physiological pH.
Ser, Tyr, Asp, Gln, Cys.
3. Amino acids with acidic side chains
These have a carboxylic acid group in their side chain and are very hydrophilic.
Asp, Glu.
4. Amino acids with basic side chains
The positive charge on these side chains makes them hydrophilic and they are likely to be found at the protein surface
Lys, Arg, His.
5. Neutral side chain
The single hydrogen atom side chain has no strong hydrophobic or hydrophilic properties.
Gly
Nucleotide Sequences
Nucleotide bases fall into two categories depending on the ring structure of the base. Purines (Adenine and Guanine) are two ring bases, pyrimidines (Cytosine and Thymine) are single ring bases. Mutations in DNA are changes in which one base is replaced by another. A mutation that conserves the ring number is called a transition (e.g., A -> G or C -> T) a mutation that changes the ring number are called transversions. (e.g. A -> C or A -> T and so on).
One-letter code Name Location
A Adenine DNA/RNA
G Guanine DNA/RNA
C Cytosine DNA/RNA
T Thymine DNA
U Uracil RNA
Nucleotide codes assigned by IUB
IUB Meaning Complement
A A T
C C G
G G C
T/U T A
M A/C K
R A/G Y
W A/T W
S C/G S
Y C/T R
K G/T M
V A/C/G B
H A/C/T D
D A/G/T H
B C/G/T V
X/N A/C/G/T X
. None .
Table of Standard Genetic Code
The genetic code in the table above has also been called "The Universal Genetic Code". It is known as "universal", because it is used by all known organisms as a code for DNA, mRNA, and tRNA. The universality of the genetic code encompases animals (including humans), plants, fungi, archaea, bacteria, and viruses. However, all rules have their exceptions, and such is the case with the genetic code; small variations in the code exist in mitochondria and certain microbes. Nonetheless, it should be emphasised that these variances represent only a small fraction of known cases, and that the genetic code applies quite broadly, certainly to all known nuclear genes.
Three of the codons do not specify the incorporation of any amino acids. These are known as the stop codons - UAA, UAG, UGA. They are found at the end of the mRNA coding sequence and they tell the ribosome to stop translating the message and release the protein. The mRNA is translated from the 5' end and read one codon at a time to the 3' end. Translation usually starts at a start codon (AUG) which codes for methionine.
|
| Second Position of Codon |
|
|
|
| T | C | A | G |
|
|
F
i
r
s
t
P
o
s
i
t
i
o
n | T | | TTT | Phe | [F] | | TTC | Phe | [F] | | TTA | Leu | [L] | | TTG | Leu | [L] | | | TCT | Ser | [S] | | TCC | Ser | [S] | | TCA | Ser | [S] | | TCG | Ser | [S] | | | TAT | Tyr | [Y] | | TAC | Tyr | [Y] | | TAA | Ter | [end] | | TAG | Ter | [end] | | | TGT | Cys | [C] | | TGC | Cys | [C] | | TGA | Ter | [end] | | TGG | Trp | [W] | | | T
h
i
r
d
P
o
s
i
t
i
o
n |
| C | | CTT | Leu | [L] | | CTC | Leu | [L] | | CTA | Leu | [L] | | CTG | Leu | [L] | | | CCT | Pro | [P] | | CCC | Pro | [P] | | CCA | Pro | [P] | | CCG | Pro | [P] | | | CAT | His | [H] | | CAC | His | [H] | | CAA | Gln | [Q] | | CAG | Gln | [Q] | | | CGT | Arg | [R] | | CGC | Arg | [R] | | CGA | Arg | [R] | | CGG | Arg | [R] | | |
| A | | ATT | Ile | [I] | | ATC | Ile | [I] | | ATA | Ile | [I] | | ATG | Met | [M] | | | ACT | Thr | [T] | | ACC | Thr | [T] | | ACA | Thr | [T] | | ACG | Thr | [T] | | | AAT | Asn | [N] | | AAC | Asn | [N] | | AAA | Lys | [K] | | AAG | Lys | [K] | | | AGT | Ser | [S] | | AGC | Ser | [S] | | AGA | Arg | [R] | | AGG | Arg | [R] | | |
| G | | GTT | Val | [V] | | GTC | Val | [V] | | GTA | Val | [V] | | GTG | Val | [V] | | | GCT | Ala | [A] | | GCC | Ala | [A] | | GCA | Ala | [A] | | GCG | Ala | [A] | | | GAT | Asp | [D] | | GAC | Asp | [D] | | GAA | Glu | [E] | | GAG | Glu | [E] | | | GGT | Gly | [G] | | GGC | Gly | [G] | | GGA | Gly | [G] | | GGG | Gly | [G] | | |

